Primarni a sekundarni index
Vygenerováno pomocí ChatGPT na základě přednášek od Holubovy
Pojmy přímé/nepřímé indexování a primární/sekundární index jsou klíčové pro efektivní organizaci a vyhledávání dat v databázových systémech. Zde je vysvětlení těchto pojmů a příklady jejich použití.
Přímé vs. Nepřímé Indexování
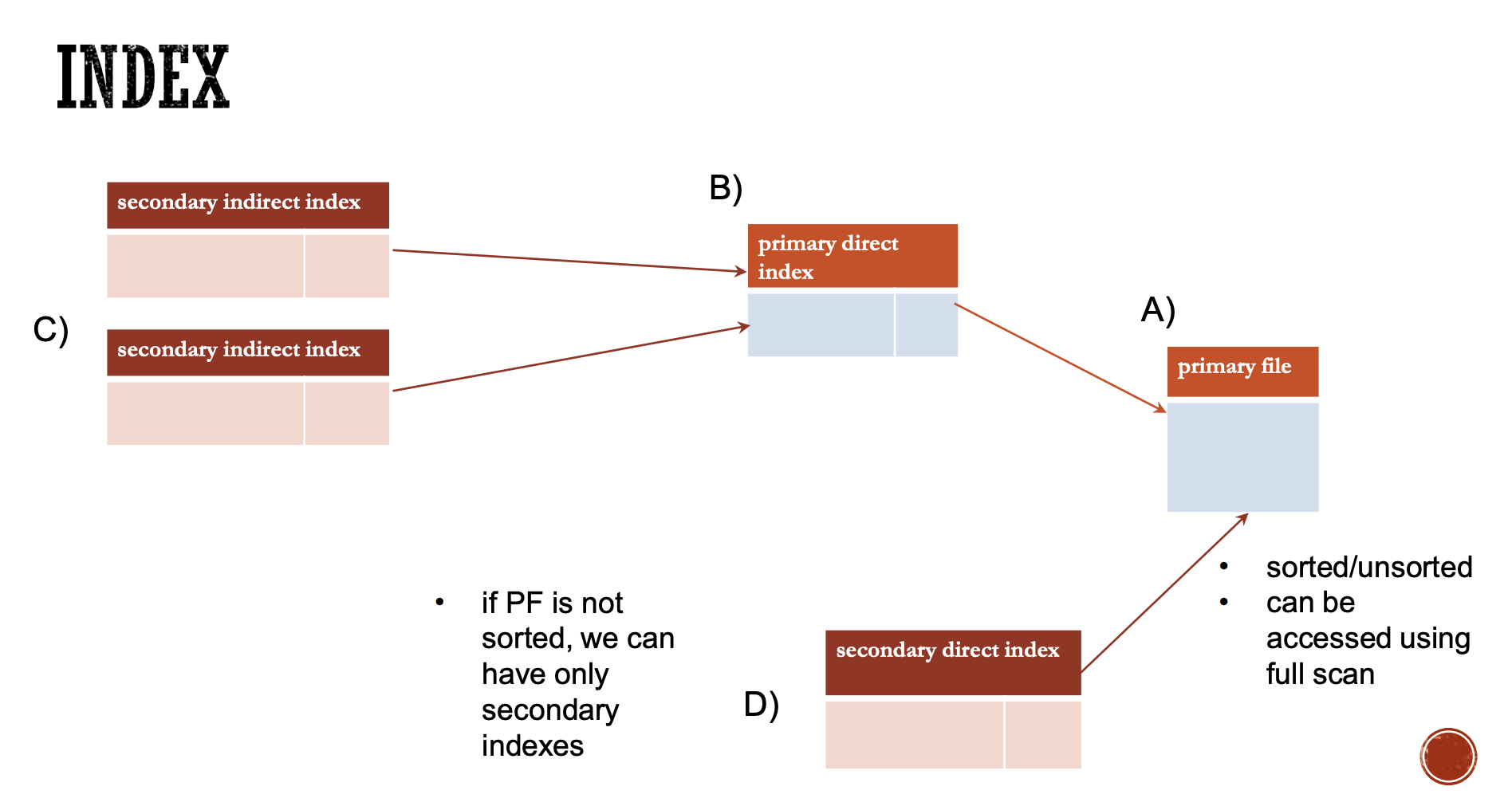
Přímé indexování (Direct Indexing):
Při přímém indexování je index přímo propojen se záznamy v primárním souboru. To znamená, že index obsahuje ukazatele přímo na záznamy v souboru, což umožňuje rychlý přístup k datům.
-
Příklad:
Představte si databázi zaměstnanců, kde každý záznam obsahuje jméno a oddělení. Při přímém indexování by index mohl obsahovat jména zaměstnanců a ukazatele na jejich záznamy v souboru. Pokud hledáte záznam pro "Galvin Janice", index by vás přímo nasměroval na příslušný blok v souboru, kde je tento záznam uložen.Struktura:
Index: - Galvin Janice -> Block 0 - Walters Rob -> Block 1Výhody:
- Rychlý přístup k záznamům díky přímému spojení mezi indexem a záznamy.
Nevýhody:
- Pokud se primární soubor reorganizuje, musí se aktualizovat i index, což může být náročné.
Nepřímé indexování (Indirect Indexing):
Nepřímé indexování neukazuje přímo na záznamy v primárním souboru, ale místo toho ukazuje na hodnoty klíče, které jsou následně použity k vyhledání záznamu. Tento typ indexování může vyžadovat dodatečný krok pro získání konečného záznamu.
-
Příklad:
Představte si stejnou databázi zaměstnanců, ale tentokrát index obsahuje klíče, které odpovídají záznamům v primárním indexu, a ne přímo záznamům v souboru. Při vyhledávání musíte nejprve získat klíč z nepřímého indexu, a poté použít tento klíč k nalezení záznamu pomocí primárního indexu.Struktura:
Sekundární nepřímý index: - Jméno -> Klíč v primárním indexu - Galvin Janice -> Key 0 - Walters Rob -> Key 1 Primární index: - Key 0 -> Block 0 - Key 1 -> Block 1Výhody:
- Nepřímé indexy zůstávají neměnné i při reorganizaci primárního souboru.
Nevýhody:
- Přístup k záznamům je pomalejší, protože vyžaduje další krok (přístup přes primární index).
Primární vs. Sekundární Index
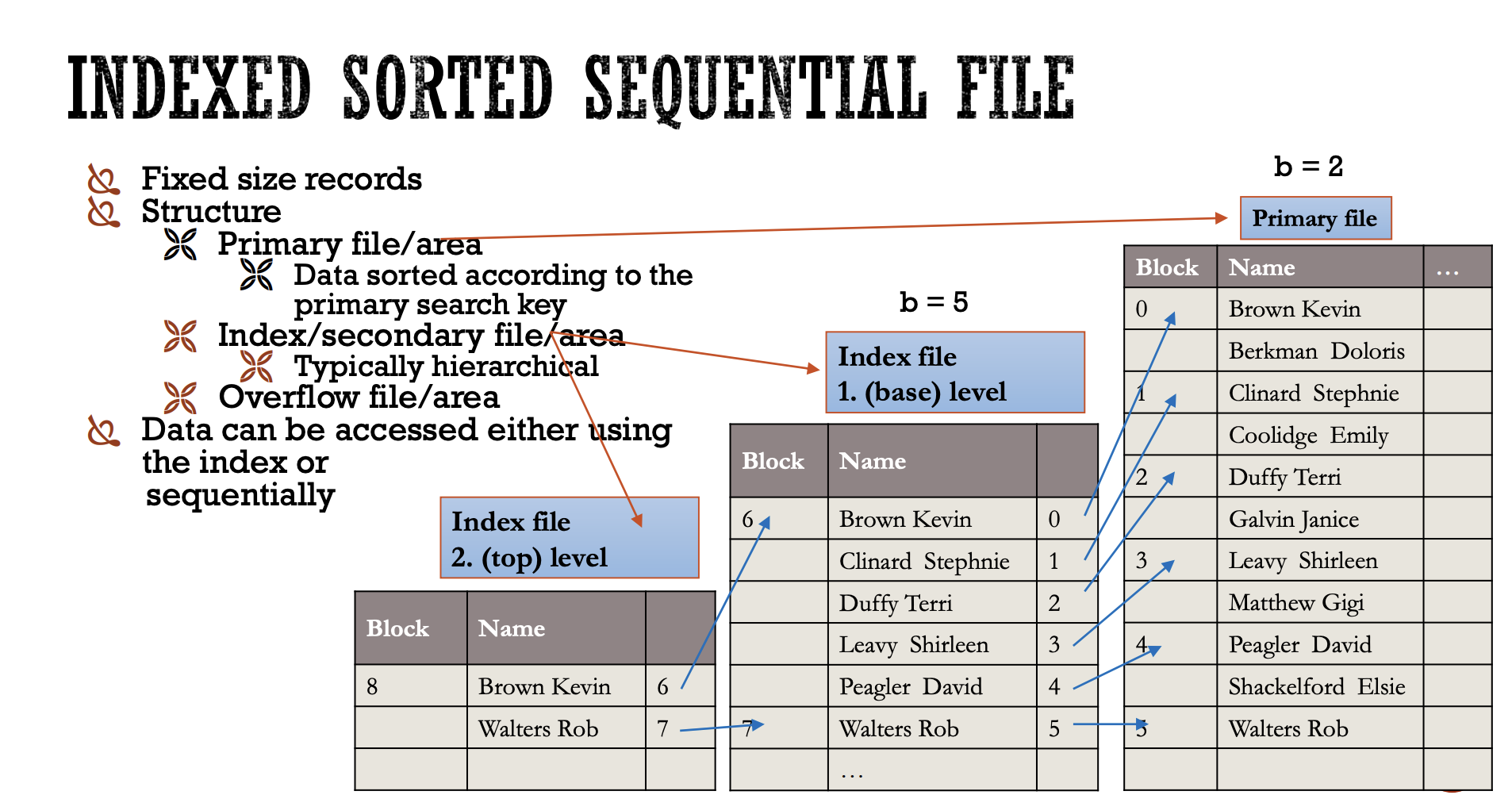
Primární index (Primary Index):
Primární index je vytvářen na atributu, podle kterého jsou záznamy v primárním souboru seřazeny. Tento index je často jediný v souboru a je používán k rychlému přístupu k datům.
-
Příklad:
Představte si, že záznamy zaměstnanců jsou seřazeny podle ID. Primární index by obsahoval ID zaměstnanců a ukazatele na příslušné bloky záznamů. Pokud chcete najít záznam pro ID "102", index by vás rychle nasměroval na správný blok.Struktura:
Primární index: - 101 -> Block 0 - 102 -> Block 1 - 103 -> Block 2Výhody:
- Rychlý přístup k záznamům díky tomu, že jsou záznamy seřazeny podle klíče indexu.
Nevýhody:
- Změna hodnoty klíče v záznamu může vést k nutnosti reorganizace celého souboru.
Sekundární index (Secondary Index):
Sekundární indexy jsou vytvářeny na atributech, které nejsou primárním klíčem. Mohou existovat více sekundárních indexů na různých atributech, což umožňuje přístup k záznamům podle různých kritérií.
-
Příklad:
Představte si, že chcete vyhledávat záznamy zaměstnanců podle věku, což není atribut, podle kterého jsou záznamy seřazeny. Sekundární index může obsahovat věk zaměstnanců a ukazatele na bloky záznamů, které tento věk mají.Struktura:
Sekundární index: - 30 -> Block 0 - 40 -> Block 1 - 50 -> Block 2Výhody:
- Umožňuje vyhledávání podle různých atributů, což zvyšuje flexibilitu přístupu k datům.
Nevýhody:
- Vyhledávání pomocí sekundárního indexu může být pomalejší, protože vyžaduje další krok pro přístup k záznamům.
Tato rozlišení a příklady ukazují, jak různé typy indexů a indexování mohou ovlivnit výkon a flexibilitu přístupu k datům v databázových systémech.