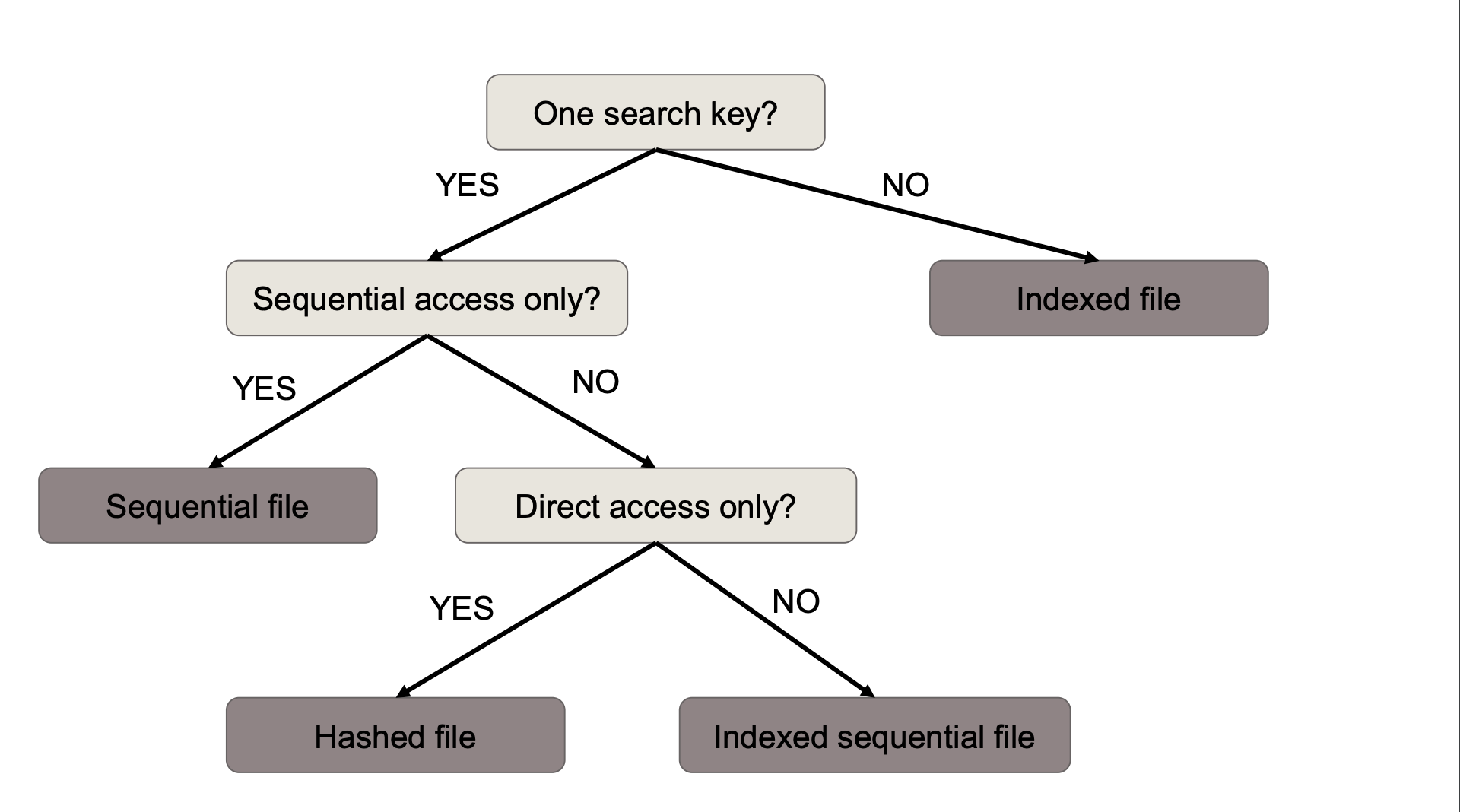
Zakladni typy organizace souboru
Vygenerováno pomocí ChatGPT na základě přednášek od Holubovy
Hromada (Heap File)
Popis:
Hromada je soubor, kde jsou záznamy ukládány v pořadí, v jakém přicházejí, bez ohledu na jejich obsah nebo klíč. Nový záznam je vždy přidán na konec souboru.
Příklad:
Představte si, že spravujete záznamy zaměstnanců, kde každý záznam obsahuje jméno, oddělení a další informace. Pokud používáte hromadu, každý nový zaměstnanec je přidán na konec souboru bez ohledu na to, v jakém oddělení pracuje.
Příklad dat v hromadě:
Block 0:
Galvin Janice - Purchasing
Walters Rob - Marketing
Brown Kevin - Marketing
Block 1:
Duffy Terri - Research
Walters David - Production
Brown Kevin - Purchasing
- Záznamy jsou ukládány postupně tak, jak přicházejí.
Výhody a nevýhody:
- Rychlé vkládání: Vkládání nového záznamu je jednoduché a rychlé, protože se záznam vždy přidá na konec souboru. (časová složitost: O(1))
- Pomalejší vyhledávání: Pokud chcete najít konkrétní záznam (např. zaměstnance jménem "Duffy Terri"), musíte prohledat celý soubor, což je časově náročné. (časová složitost: O(N/b), kde (N) je počet záznamů a (b) je blokovací faktor)
Sekvenční soubor (Sequential File)
Popis:
Sekvenční soubor ukládá záznamy v souboru buď seřazené podle určitého klíče, nebo neseřazené. Záznamy jsou uloženy v pořadí, v jakém přicházejí (neseřazené), nebo podle určitého atributu (seřazené).
Seřazený sekvenční soubor (Sorted Sequential File)
Popis:
Záznamy jsou v souboru uspořádány podle jednoho klíče, často primárního klíče, který se používá k jejich vyhledávání. Například záznamy mohou být seřazeny podle identifikátoru, jména nebo data.
Příklad:
Představte si soubor se záznamy zákazníků seřazenými podle jejich ID.
Příklad dat v seřazeném sekvenčním souboru:
Block 0:
101 - Brown Kevin - PR
102 - Duffy Terri - Research
Block 1:
103 - Galvin Janice - Purchasing
104 - Walters Rob - Marketing
- Záznamy jsou seřazeny podle ID zákazníků (primárního klíče).
Výhody:
- Efektivní vyhledávání: Seřazené záznamy umožňují rychlé vyhledávání pomocí binárního vyhledávání. (časová složitost: O(log(N/b)))
- Podpora rozsahových dotazů: Dotazy, které vyžadují všechny záznamy v určitém rozsahu (např. záznamy mezi ID 101 a 104), mohou být zpracovány efektivně.
Nevýhody:
- Náročné vkládání: Vkládání nových záznamů může vyžadovat posun existujících záznamů, aby bylo zachováno správné pořadí. (časová složitost: O(N/b))
- Složitá údržba: Aktualizace záznamů, které mění hodnotu klíče, vyžadují reorganizaci souboru.
Neseřazený sekvenční soubor (Unsorted Sequential File)
Popis:
V neseřazeném sekvenčním souboru jsou záznamy ukládány v pořadí, v jakém přicházejí, bez ohledu na hodnotu klíče. Tento typ je podobný hromadě, ale může být konstruován pro specifické případy použití, kde je potřeba sekvenční přístup.
Příklad:
Představte si soubor s objednávkami, kde záznamy jsou ukládány podle pořadí jejich přijetí, bez ohledu na datum nebo číslo objednávky.
Příklad dat v neseřazeném sekvenčním souboru:
Block 0:
103 - Walters Rob - Marketing
101 - Brown Kevin - PR
Block 1:
104 - Galvin Janice - Purchasing
102 - Duffy Terri - Research
- Záznamy nejsou seřazeny podle ID nebo jiného atributu.
Výhody:
- Rychlé vkládání: Nové záznamy lze jednoduše přidat na konec souboru, což je efektivní. (časová složitost: O(1))
- Jednoduchá implementace: Nepotřebujete složité operace pro vkládání nových záznamů.
Nevýhody:
- Pomalejší vyhledávání: Pokud potřebujete najít konkrétní záznam, musíte provést sekvenční prohledávání, což je časově náročné. (časová složitost: O(N/b))
- Nevhodné pro rozsahové dotazy: Rozsahové dotazy jsou obtížně zpracovatelné, protože záznamy nejsou seřazeny.
Shrnutí:
-
Seřazený sekvenční soubor je vhodný pro aplikace, kde jsou záznamy často vyhledávány podle konkrétního klíče a kde je vyžadováno efektivní zpracování rozsahových dotazů. Na druhou stranu je náročnější na údržbu při vkládání nových záznamů.
-
Neseřazený sekvenční soubor je vhodný pro aplikace, kde je potřeba jednoduché a rychlé vkládání záznamů a není kladen důraz na rychlé vyhledávání. Vyhledávání v takovém souboru je však pomalejší a méně efektivní pro rozsahové dotazy.
Oba přístupy mají své specifické výhody a nevýhody v závislosti na konkrétních požadavcích na přístup k datům a jejich zpracování.
Indexovaný sekvenční soubor (Indexed Sequential File)
Popis:
Tento typ souboru kombinuje výhody sekvenčního souboru a indexu. Data jsou seřazena podle primárního klíče a navíc je vytvořen index, který umožňuje rychlejší přístup k záznamům.
Příklad:
Představte si, že máte záznamy zaměstnanců seřazené podle jména, a k tomu je vytvořen index pro rychlý přístup.
Příklad dat v indexovaném sekvenčním souboru:
Primární soubor:
Block 0:
Brown Kevin - PR
Brown Kevin - Purchasing
Block 1:
Duffy Terri - Research
Galvin Janice - Purchasing
Block 2:
Walters Rob - Marketing
Walters Rob - Development
Index:
Level 1 (Top Index):
Brown Kevin -> Block 0
Duffy Terri -> Block 1
Walters Rob -> Block 2
- Index vám umožňuje rychle najít správný blok dat podle primárního klíče.
Výhody a nevýhody:
- Rychlé vyhledávání: Pomocí indexu můžete rychle najít blok, který obsahuje hledaný záznam, což zrychluje vyhledávání. (časová složitost: O(log(N/b)))
- Složitější údržba: Když přidáváte nový záznam nebo měníte existující, musíte aktualizovat jak primární soubor, tak index, což může být náročné na čas a prostředky.
Shrnutí:
- Hromada je vhodná pro jednoduché a rychlé vkládání záznamů bez ohledu na pořadí, ale není efektivní při hledání.
- Sekvenční soubor nabízí efektivní vyhledávání, pokud jsou záznamy seřazeny podle často používaného klíče, ale jeho údržba při přidávání nových záznamů je složitější.
- Indexovaný sekvenční soubor kombinuje výhody sekvenčního souboru s rychlým přístupem pomocí indexu, ale vyžaduje složitější správu a údržbu.