Techniky vizualizace výsledků hledání v gridu pomocí různých technik zobrazení rankované množiny
Vygenerováno pomocí ChatGPT na základě přednášek
Techniky vizualizace výsledků hledání v gridu pomocí různých technik zobrazení rankované množiny
1. Rankovaná množina
Rankovaná množina představuje uspořádání datových bodů (například výsledků hledání) na základě jejich relevance k zadanému dotazu. Každý datový bod je ohodnocen (rankován) podle určité metriky, která určuje jeho pořadí. V gridové vizualizaci se tyto body uspořádají podle jejich ranku, obvykle od nejrelevantnějších (nejvyšší hodnocení) po méně relevantní.
Vizualizace rankované množiny:
Techniky vizualizace výsledků hledání v gridu pomocí zobrazení rankované množiny jsou klíčové pro usnadnění uživatelského přístupu k relevantním informacím. Různé techniky zobrazení umožňují efektivní uspořádání objektů na základě jejich relevance, což zvyšuje uživatelskou přívětivost a rychlost nalezení požadovaných výsledků. Níže jsou popsány některé z hlavních technik:
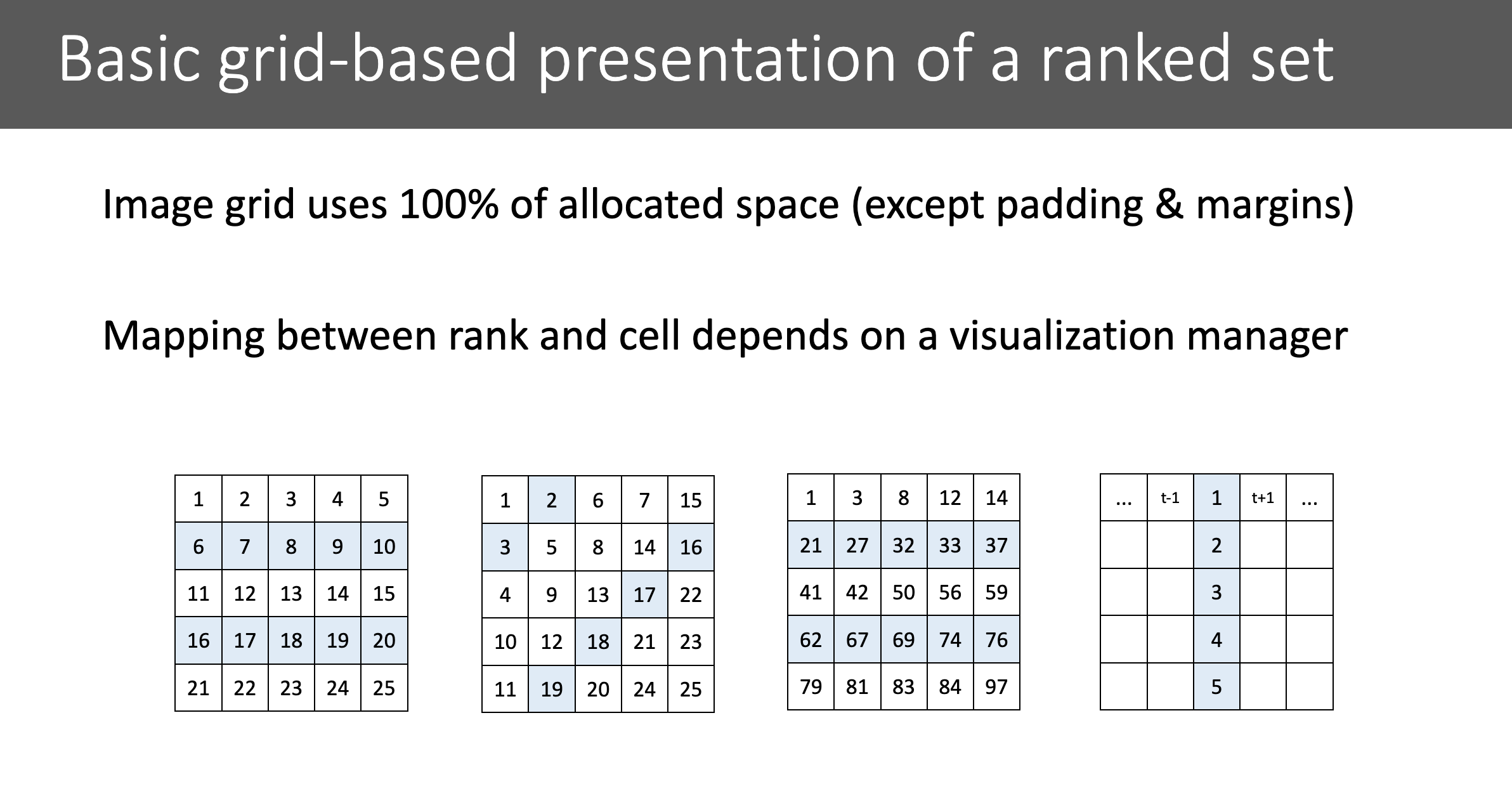
1. Standardní grid
- Popis: Výsledky jsou uspořádány v jednoduché mřížce, kde jsou objekty řazeny podle relevance odshora dolů a zleva doprava.
- Výhody: Intuitivní a jednoduché na pochopení. Uživatelé mohou snadno procházet výsledky.
- Nevýhody: Může být neefektivní při velkém počtu objektů, protože uživatelé musí často procházet mnoho výsledků, aby našli ty nejrelevantnější.
2. Zvýraznění rohů
- Popis: Objekty s nejvyšší relevancí jsou umístěny v rozích nebo středu gridu, kde je větší pravděpodobnost, že na ně uživatel klikne.
- Výhody: Tato technika zvyšuje šanci, že si uživatel všimne a klikne na nejdůležitější výsledky.
- Nevýhody: Může být méně intuitivní, protože uživatelé mohou očekávat nejrelevantnější výsledky na jiných místech (například nahoře).
3. Progresivní zveřejnění (Zig-Zag vzor)
- Popis: Tento přístup uspořádává výsledky v zig-zag vzoru, což může být efektivní pro zobrazování časově nebo kontextově řazených dat.
- Výhody: Pomáhá vizualizovat a sledovat časové nebo sekvenční vztahy mezi objekty, což je užitečné v aplikacích, kde je sledování pořadí důležité.
- Nevýhody: Může být méně přehledný pro uživatele, kteří nejsou obeznámeni s tímto typem uspořádání.
4. Self-Sorting Map (SSM)
- Popis: Algoritmus organizuje data v gridu tak, aby podobná data byla umístěna blízko sebe. Toto je zvláště užitečné při vizualizaci obrázků, kde chceme, aby vizuálně podobné obrázky byly ve stejné oblasti gridu.
- Výhody: Umožňuje uživatelům rychle najít podobné objekty bez nutnosti procházet celou množinu.
- Nevýhody: Vyžaduje složitější algoritmy pro správné uspořádání dat, což může být náročné na výpočetní zdroje.
5. Techniky zvýraznění relevance
- Popis: Zvýraznění nejrelevantnějších objektů pomocí vizuálních efektů, jako jsou větší velikost, jiné barvy nebo animace.
- Výhody: Uživatelé rychle rozpoznají nejdůležitější výsledky.
- Nevýhody: Příliš mnoho zvýraznění může vést k vizuálnímu přetížení a snížení uživatelské přehlednosti.
6. Časově a kontextově zaměřené zobrazení
- Popis: Zobrazuje výsledky v kontextu jejich časového nebo jiného vztahu, například podle data nebo tématu.
- Výhody: Užitečné v aplikacích, kde je důležité sledovat souvislosti mezi výsledky.
- Nevýhody: Může být méně efektivní pro obecné vyhledávání, kde čas nebo kontext nejsou klíčové.
Příklad:
Pokud máte výsledky vyhledávání obrázků na základě dotazu "hory", výsledky mohou být seřazeny od nejvíce k nejméně relevantním obrázkům, přičemž nejrelevantnější jsou umístěny v horním levém rohu mřížky.
2. Self-sorting map (SSM)
Self-sorting map (SSM) je technika, která automaticky seřadí prvky na 2D gridu podle určitého kritéria podobnosti. Cílem je, aby prvky, které jsou si podobné, byly na mřížce co nejblíže, což umožňuje vizuálně odlišit různé klastry dat.
Vizualizace pomocí SSM:
- Automatické uspořádání: SSM automaticky přiřadí každému datovému bodu místo na gridu na základě podobnosti s ostatními body. Body, které jsou si podobné, jsou umístěny blízko sebe, což vytváří klastery.
- Interaktivní vizualizace: Uživatel může prozkoumat různé části mřížky, kde každý klastr reprezentuje podobnou skupinu dat. To umožňuje snadnou identifikaci a analýzu podobných výsledků.
Příklad:
Pokud vizualizujete výsledky vyhledávání obrázků, SSM může umístit obrázky s podobnou barevností nebo kompozicí vedle sebe, čímž se vytvoří klastery, například všechny obrázky s dominantní modrou barvou budou blízko u sebe.
3. Self-organizing map (SOM)
https://www.youtube.com/watch?v=H9H6s-x-0YE
Self-organizing map (SOM) je umělá neuronová síť, která se používá k vizualizaci a organizaci dat na 2D gridu. SOM vytváří mapu, kde jsou podobné datové body umístěny blízko sebe, což umožňuje vizualizovat a analyzovat strukturu dat.
Vizualizace pomocí SOM:
- Topologické uspořádání: SOM udržuje topologii dat, což znamená, že podobná data jsou umístěna vedle sebe. Grid tak reflektuje strukturu datové množiny.
- Barvové nebo tvarové označení: Pro zvýraznění různých klastrů na SOM lze použít různé barvy nebo tvary. To umožňuje snadnější identifikaci oblastí s vysokou koncentrací podobných výsledků.
Jak funguje přirazení klasifikace
Máme 2D grid s
Pro vsechny vstupy:
Vezmeme nahodny vstup
Spocitame pro nej vitezny neuron (klasifikaci)
Upravime vzdalenost neuronu (vsech protoze neurony na sobe zavisi)
Vratime klasifikace pro vsechny vstupy
Příklad:
Pokud máte velkou množinu obrázků různých druhů ovoce, SOM může uspořádat obrázky tak, že obrázky stejného ovoce budou blízko sebe, a výsledná mřížka bude mít oblasti reprezentující různé druhy ovoce (např. oblast s jablky, oblast s pomeranči).
Shrnutí
Každá z těchto technik má své specifické výhody pro vizualizaci rankované množiny výsledků:
- Rankovaná množina je jednoduchá a přímočará, ideální pro lineární nebo sekvenční zobrazení dat.
- Self-sorting map poskytuje více dynamické a interaktivní zobrazení, kde jsou data automaticky seřazena podle podobnosti, což je užitečné pro zkoumání různých klastrů.
- Self-organizing map umožňuje vizualizovat komplexní strukturu dat a zachovává topologické vztahy, což je ideální pro analýzu velkých a složitých množin dat.
Tyto techniky jsou vhodné pro různé scénáře a umožňují efektivní organizaci a vizualizaci dat v gridovém formátu, čímž zvyšují přehlednost a usnadňují vyhledávání relevantních informací.
Key Differences:
- SOM: The output is a topologically organized 2D grid, emphasizing the preservation of relationships in high-dimensional data.
- SSM: Focuses more on arranging data in a 2D grid based on predefined similarity measures, without necessarily involving a learning process like SOM.